
Network resilience is a key requirement for modern telecommunications providers — and that’s particularly true when the carrier operates a fiber-optic network. The interdependence of business processes and the network, combined with an increasing number of natural disasters and manmade fiber cuts, has made the ability of the fiber infrastructure to quickly recover vital. Service providers are moving towards mesh-based transport networks, and the latest technological advance is the standards-based Shared Mesh Protection, which leverages an intelligent GMPLS control plane so a meshed transport network can recover from multiple local and network-wide failures while lowering costs by avoiding the need to dedicate backup bandwidth for every active circuit. This article will examine hardware-accelerated Shared Mesh Protection as a means of increasing the network resiliency without incurring additional fiber-related expenses.
In India’s fast developing economy there is the constant churn of building, demolition and road work, putting existing telecom infrastructure at risk. According to industry sources, the Tier-1 operator in India experience twelve to fifteen fibre cuts per thousand km per month. To put this in the context, consider the fact that the Top Tier-1 operators in India own anywhere from 80 to 190 thousand Kms of fiber. This works out to over 60 fibre cuts a day, 2000 every month or 25,000 fibre cuts each year that these operators have to deal with while, in a globalized economy, customer expectations get benchmarked with the best in the world. This adds significant challenges for the Tier-1 operators in terms of increased OpEx for fiber repair, increased CapEx for the traditionally available optical protection to deal with fiber cuts and, increased spending for customer retention.
As bandwidth continues to grow at staggering rates, estimated at 40% growth year over year globally, driven by business applications like cloud, mobile, and video technologies, any single outage of just 50 minutes in a year drops network availability down to four nines, or 99.99%. Whatever the reason for network outages, it falls to the service provider to fix the problems. In this effort there are generally two approaches:
- Protection. This must occur within 50ms of the failure (the accepted gold standard for recovery). In order to achieve this rapid response, it is typical to use a pre-computed path for protection circuits. Protection capacity may be dedicated, or it may be switched. However, there are quite stringent limitations for traditional switched protection protocols in terms of topology and scalability. There may also be limitations on protecting against multiple failures.
- Restoration. In a restoration operation when the fault is detected, a new path is computed, and connections are taken down from the working path and reestablished on the backup path. Restoration is common in packet networks, and while it may be comparatively slow (typically measured in seconds to minutes), it allows protection capacity to be shared, and will almost always find a way through as long as a backup path exists. Restoration is also possible at the digital transport layer, with performance improvements varying from hundreds of milliseconds to a few seconds, but still falling far short of the sub-50 millisecond failure recovery requirement.
Today, the above approaches are realized using the below resilience techniques:
- SONET/SDH: 1+1 and Sub-Network Connection Protection (SNCP) uses dedicated protection bandwidth to provide guaranteed sub-50ms protection for all payload types (SONET/SDH, Ethernet, SAN, video). This protection is used in the transport networks of many carriers today. This type of protection defined the 50ms value, but it does not offer protection against multiple failures, and the way that it is implemented normally means that protection capacity cannot be shared by other services, thus, increasing costs.
- Digital OTN/GMPLS: Software Mesh Restoration is provided by newer intelligent optical cross-connect switches as an alternative to using dedicated bandwidth for protection. When a failure occurs, these devices use intelligent control planes to reroute the affected services using software-based tables that use unallocated bandwidth in the network. Since all unallocated bandwidth is available as a shared pool of restoration bandwidth, this mechanism is typically 20-35% more efficient in terms of network resources as compared to dedicated protection bandwidth. In addition, because GMPLS mesh restoration dynamically reroutes a failed service based on available bandwidth, this procedure can be repeated in the case of multiple failures in the network. However, the multi-stage, software-only approach can take seconds to recover and overall restoration time will increase with the complexity of the network topology, the number of links, and the number of restorable connections.
- Packet IP/MPLS: Fast Re-Route (FRR) is a router-based protection used in data-centric networks. Like GMPLS mesh restoration, MPLS FRR uses shared protection bandwidth for network efficiency and can recover from multiple failures. One of the goals for MPLS has always been to offer enhanced resilience compared to connectionless IP networks. MPLS FRR (sometimes referred to as MPLS Local Protection) allows a Label Switch Router the possibility to react within 50ms with a local detour once it detects a fault on the working path. MPLS FRR uses pre-computed Label Switched Paths and label values, so all that has to be done is that an LSR uses a new label and directs the traffic out of a different port. MPLS FRR allows an arbitrary topology to be used and is a shared protection technique. The drawbacks with MPLS FRR are that sub-50ms operation is not fully deterministic because it is only local and once the failure occurs, the entire network may need to re-converge, and that it makes use of additional expensive IP/MPLS router ports to achieve resilience.
The case for hardware-accelerated Shared Mesh Protection
As we have seen, networks are now facing multiple failures and single failure protection is no longer sufficient. Additionally, solving a multi-failure scenario is simply too costly in the face of rising traffic across fibers that can be carrying up to 8 Tb/s of capacity. The pricing pressures faced by service provider business models demand a new approach to resilience.
The ideal resilience technology for modern transport networks should offer three fundamental capabilities:
- Multi-failure recovery for better survivability;
- Fast recovery within 50ms for deterministic performance; and
- Intelligent sharing of backup resources for better economics.
These three capabilities are now available in a single technology of the hardware-accelerated Shared Mesh Protection. This solution offers service providers the opportunity to create tiered protection plans, which could help generate additional revenue for a minimum investment in protection capacity.
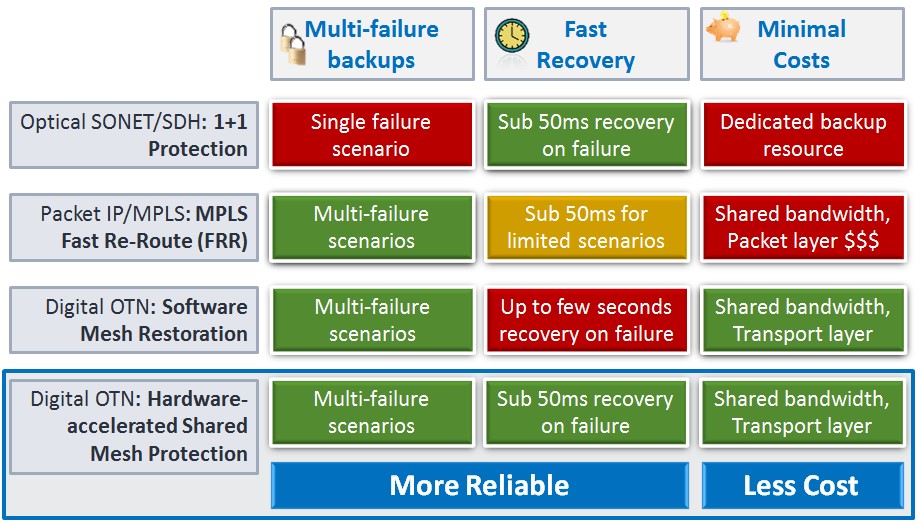
Figure 1: Comparison of resilience capabilities in major network technologies
Today, the ITU-T is working on two documents: G.SMP (G.808.3) and G.ODUSMP. The former protocol aims to standardize the technology-independent portions of SMP, while the latter aims to standardize it for the digital OTN layer. The protocols cover message encoding, signaling, activation and other functions necessary to achieve SMP. Meanwhile, IETF is working on two drafts to standardize its application across digital circuit and packet network.
The SMP protocol is fundamentally a proactive approach for network protection. It decouples time-critical tasks like protection activation from longer timescale, heavier processing GMPLS control plane route computation. The SMP protection activation protocol is designed to be lightweight, and this is a key characteristic that enables it to be implemented in hardware, supporting thousands of services and providing fast recovery.
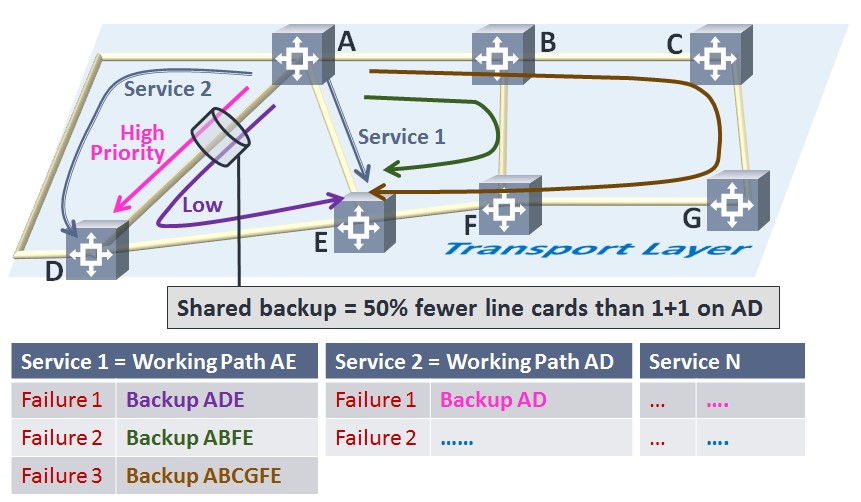
Figure 2: 1+1 Dedicated Protection vs. SMP
How it works and the importance of hardware acceleration
While long haul transmission is rapidly moving to coherent 100 Gb/s and 500 Gb/s superchannel technology, service demands are still predominantly made up of extremely large numbers of gigabit Ethernet and 10GbE. With the move to 100G and 8 Tb/s of capacity per fiber, a single fiber cut could affect many thousands of services. Customers plan to use backbone transport platforms for more than a decade and require them to be built ground up to handle multi-terabit scale at a highly granular service level while providing unmatched bandwidth efficiency and resilience. This new design allows SMP to be implemented using dedicated hardware acceleration processors that support 50ms recovery of thousands of services simultaneously, even in the face of multiple fiber cuts. Infinera implements this technology on the DTN-X transport platform using its FastSMP processor, that’s built into every board every shipped. It implements a massively parallel pipelined architecture supporting networks with thousands of nodes, with multiple hops and recovering from multi-terabit fiber capacity failure. The failure scenarios are handled at a highly granular level (i.e. per service).
Not surprisingly, the orchestration of high numbers of service demands with a sophisticated protection hierarchy has to be supported within a powerful planning system. The first step for SMP is, therefore, to use Network Planning System (NPS) software to pre-calculate multi-failure scenarios, and then to populate the hardware tables contained in the FastSMP Processor. This is the key to ensuring the 50ms end-to-end protection capability.
Once a failure occurs, the FastSMP Processor will ensure protection activates in less than 50ms. At the same time, the failure notification prompts GMPLS intelligence in each node to start recalculating backup paths in real time, and then continuously updates both the hardware tables across the network and the NPS if required. Thus, the three key components, NPS, the FastSMP Processor, and the GMPLS Control Plane, are always in sync.

Figure 3: Infinera FastSMP solution components
Monetizing the technology
The hardware-accelerated SMP technology may be employed in fully meshed and partially meshed transport networks, which include, but are not limited to, long-haul and metro networks. Depending on the degree of inter-connection between network nodes, SMP protection can significantly improve network resource utilization, as compared with alternative protection mechanisms. A recent study by ACG Research shows savings of 33% can be achieved using SMP instead of 1+1 protection.
Also, this technology affords an opportunity to offer a variety of new protection tiers. Carriers are starting to examine the following different tiers:
- Premier: survivable with “hitless” performance of two network failures with highest priority;
- Elite: survivable with “hitless” performance of one network failure; best effort restoration for additional network failures;
- Protected: survivable with “hitless” performance of one network failure;
- Restorable: best effort restoration for any network failures;
- Unprotected: not survivable after a network failure, but not pre-emptible; and
- Best effort: lowest priority and pre-emptible by higher priority services.
At a minimum, SMP can provide a carrier a more competitive posture in the marketplace, enabling them to acquire and retain key customer revenue streams.
Conclusion
With the interconnectedness of business operations and network reliability intersecting with an increasing number of natural and man-made threats to fiber networks, service providers need to take advantage of new protection capabilities afforded by network intelligence, hardware innovation and mesh network topologies. The hardware-accelerated SMPsolution combines the following three foundation resilience capabilities into a single technology:
- Enhanced availability: automatic multi-failure network-wide backup via network intelligence;
- Deterministic performance: sub 50ms recovery via dedicated hardware; and
- Lower capital costs and operations: shared backups via cost-effective transport layer.
Thanks to this capability, service providers can continue to offer stringent SLAs to their end customers for protected services, and even create a hierarchy of protection classes that will provide vital service differentiation and additional revenue opportunities. It can also prevent retired pensioners who have never heard of the Internet from knocking off Web services for millions.
To find out more visit http://www.infinera.com/technology/fastsmp/
